📌 2주차 : SQL
- SQL
- DDL, DML, DCL, TCL
📌 1. SQL이란? 프로그래밍 언어와의 차이점은 무엇인가?
📌 2. 개발자가 작성한 SQL이 어떤 과정을 통해 실행 되는 것인가?
📌 3. DML, DDL, DCL은 무엇인가요? 어떤 구문이 있나요?
📌 4. 참조 무결성에 대해서 설명해주세요.
📌 5. CASCADE 설정에 대해서 설명해주세요.
📌 6. VIEW에 대해서 설명해주세요.
📌 7. SELECT 절의 처리순서에 대해서 설명해주세요.
📌 8. SELECT ~ FOR UPDATE 구문에 대해서 설명해주세요.
📌 9. GROUP BY절에 대해서 설명해주세요.
📌 10. ORDER BY절에 대해서 설명해주세요.
📌 11. INNER JOIN과 OUTER JOIN의 차이점에 대해서 설명해주세요.
📌 12. LEFT OUTER JOIN, RIGHT OUTER JOIN에 대해서 설명해주세요.
📌 13. CROSS JOIN에 대해서도 설명해주세요.
📌 14. 서브쿼리에 대해서 설명해주세요.
📌 15. DROP, TRUNCATE, DELETE에 각각에 대해 설명해주세요. 어떤차이가 있나요?
📌 16. DISTINCT에 대해서 설명해주세요. 사용해본 경험도 설명해주세요.
📌 17. SQL Injection 공격이 무엇인지 어떻게 공격을 예방할 수 있는지 설명해주세요.
📌 18. 알고 있는 SQL 안티패턴이 있다면 설명해주세요.
📌 19. 페이지네이션을 구현한다고 했을때 쿼리를 어떻게 작성해야할까요?
📌 1. SQL이란? 프로그래밍 언어와의 차이점은 무엇인가?
Structured Query Language.
관계형 데이터베이스에서 사용되는 데이터베이스를 조작하는 언어입니다.
DBMS는 데이터베이스를 관리하는 소프트웨어입니다.
DBMS를 이용하면 간접적으로 데이터베이스를 참조할 수 있고, 데이터를 추가하거나 삭제, 갱신할 수도 있습니다.
DBMS와의 대화에 필요한 것이 바로 SQL입니다.
데이터베이스에도 몇 가지 종류가 있지만
SQL은 그중 관계형 데이터베이스 관리 시스템(DBMS)을 조작할 때 사용합니다.
관계형 DBMS를 배우려면 SQL을 익혀야합니다.
SQL이 데이터베이스를 조작하는 언어이긴 하지만
일반적인 프로그래밍 언어 (C, 자바, 파이썬 등)와는 조금 다른 특성을 갖습니다.
SQL은 비절차적(선언적) 언어이므로 찾는 데이터만 기술하고 처리과정을 기술할 필요가 없습니다.
하지만 C, JAVA와 같은 프로그래밍 언어는 절차적 언어이기 때문에 개발자가 처리절차를 일일이 기술해야 합니다.
• 절차적 언어: 어떤 데이터가 필요하고 어떻게 데이터를 찾을 것인가를 명시.
개발자가 처리 순서를 처음부터 끝까지 정해줘야한다.(ex : JAVA, C)
• 비절차적 언어(선언적 언어): 어떤 데이터를 원하는가만 명시하고 데이터를 검색하는 방법은 명시하지 않음.
개발자가 처리절차를 지정하지 않고 원하는 결과를 정의하여 요청한다. (ex : SQL)
SQL은 특정 회사에서 만드는 것이 아니라, 국제표준화기구에서 SQL에 대한 표준을 정해 발표하고 있습니다.
이를 표준 SQL이라고 합니다. 그런데 문제는 SQL을 사용하는 DBMS를 만드는 회사가 여러 곳이기 때문에 표준 SQL이 각 회사 제품의 특성을 모두 포용하지 못한다는 점입니다.
그래서 DBMS를 만드는 회사에서는 되도록 표준 SQL을 준수하되, 각 제품의 특성을 반영한 SQL을 사용합니다.
📌 2. 개발자가 작성한 SQL이 어떤 과정을 통해 실행 되는 것인가?
1) SQL문 작성 및 제출
개발자는 SQL문을 작성하여 데이터베이스 서버로 전송합니다.
2) SQL 파싱
데이터베이스의 SQL파서가 SQL문을 받아서 구문 분석을 수행합니다.
이 과정에서 SQL문의 문법적 올바름을 검사합니다.
3) 최적화
SQL 최적화기는 파싱된 쿼리를 가지고 실행 계획을 생성합니다. 이 단계에서 여러 실행 경로를 고려하여 가장 효율적인 방법을 선택합니다.
4) 컴파일
최적화된 실행 계획은 컴파일되어 실행 가능한 형태로 변환됩니다.
5) 실행
컴파일된 실행 계획은 데이터베이스 관리 시스템에 의해 실행됩니다. 이때, 스토리지 엔진이 디스크나 메모리에서 필요한 데이터를 검색하고 조작합니다.
6) 결과 반환
SQL문의 실행이 완료되면, 결과는 데이터베이스 서버로부터 개발자 또는 해당 어플리케이션으로 반환됩니다.
전체 과정에서 데이터베이스 서버의 여러 구성 요소가 상호 작용하며,
SQL문이 효율적으로 처리되도록 합니다.
데이터베이스의 성능은 이러한 과정들이 얼마나 잘 최적화되어 실행되는지에 크게 의존합니다.
📌 3. DML, DDL, DCL은 무엇인가요? 어떤 구문이 있나요?
SQL 명령은 크게 위와 같이 3가지로 나뉠 수 있습니다.
DML
Data Manipulation Language
데이터베이스에 새롭게 데이터를 추가하거나 삭제하거나 내용을 갱신하는 등 데이터를 조작할 때 사용합니다.
SQL의 가장 기본이 되는 명령셋(set)입니다.
* 구문 : SELECT, INSERT, UPDATE, DELETE, MERGE, CALL, EXPLAIN PLAN, LOCK TABLE
DDL
Data Definition Language
데이터를 정의하는 명령어입니다.
데이터베이스는 데이터베이스 객체라는 데이터 그릇을 이용하여 데이터를 관리하는데, 이 같은 객체를 만들거나 삭제하는 명령어입니다.
* 구문 : CREATE, ALTER, DROP, RENAME, COMMENT, TRUNCATE
DCL
Data Control Language
데이터를 제어하는 명령어. DCL에는 트랜잭션을 제어하는 명령과 데이터 접근권한을 제어하는 명령이 포함되어 있습니다.
* 구문 : GRANT, REVOKE
📌 4. 참조 무결성에 대해서 설명해주세요.
데이터베이스 상의 참조가 모두 유효함을 일컫습니다.
관계형 데이터베이스에서 하나의 속성이 다른 테이블의 속성을 참조하고 있다면,
참조한 해당 속성이 반드시존재해야합니다.
구체적으로 설명하자면
릴레이션 간의 참조 관계를 정의하는 제약조건으로 외래키는 참조할 수 없는 키를 가질 수 없다는 것입니다.
외래키 값은 참조하는 릴레이션의 기본키 값과 동일해야하거나 NULL이어야합니다.
각 릴레이션은 참조할 수 없는 외래키 값을 가질 수 없습니다.
예를 들어, 수강 릴레이션에서 학번 속성에는 학생 릴레이션의 학번 속성에 없는 값은 입력할 수 없습니다.
이렇게 참조 무결성을 통해 PK와 FK간의 관계가 항상 유효하도록 관리합니다.
따라서, PK를 참조하는 FK가 있다면, 해당 PK는 수정과 삭제가 불가능합니다.
📌 5. CASCADE 설정에 대해서 설명해주세요.
* 사전적 의미 CASCADE : 작은 폭포, 종속, 연속 등등
참조 무결성으로 PK를 참조하는 FK가 있다면,
해당 PK를 수정하거나 삭제하는 것은 불가능합니다.
그렇다면 어떻게 해야 PK값을 수정하거나 행을 삭제할 수 있는 것일까요?
한가지 방법으로 FK의 참조값을 NULL로 만들어서 참조를 모두 끊은 후,
필요한 수정과 삭제를 진행하는 것입니다.
하지만 해당 방법은 FK에 NUT NULL 제약 조건이 걸려있다면 활용할 수 없고,
정확하게 모든 쿼리를 날려야하기 때문에 위험한 방법입니다.
이러한 상황에서 사용하는 옵션이 CASCADE 옵션입니다.
DB의 값을 수정/삭제할 때,
해당 값을 참조하고 있는 행 역시 종속적으로 수정/삭제를 가능하게 해줍니다.
기존에 PLAYER, TEAM이라는 테이블이 있다는 가정 하에 아래와 같이 SQL 작성하여
PK가 수정이 되었을 때 외래키로 연결된 아이디도 함께 수정이 되도록 할 수 있습니다.
ALTER TABLE PLAYER DROP CONSTRAINT CONSTRAINT_8CD;
ALTER TABLE PLAYER ADD FOREIGN KEY (team_id) REFERENCES TEAM (id) ON UPDATE CASCADE;
이렇게 테이블을 변경하고
UPDATE TEAM SET id = 2 WHERE team_name = 'CHELSEA';
위와 같이 실행하면
TEAM 테이블의 CHELSEA 로 설정되어있는 PLAYER 테이블의 선수의 팀 아이디도 CHELSEA의 아이디로 자동으로 변경이 됩니다.
삭제의 경우도 마찬가지입니다.
ALTER TABLE PLAYER DROP CONSTRAINT CONSTRAINT_8CD;
ALTER TABLE PLAYER ADD FOREIGN KEY (team_id) REFERENCES TEAM (id) ON DELETE CASCADE;
테이블을 변경 후
DELETE FROM TEAM where id = 1;
실제 삭제를 하면 해당 팀에 소속되어 있는 선수들도 모두 삭제가 됩니다.
그러나, 삭제의 경우 팀이 없어졌다고해서 꼭 선수들까지 없어질 필요가 없을 수도 있으니
ON DELETE CASCADE를 ON DELETE SET NULL; 로 표현합니다.
ON DELETE SET NULL은 참조하고 있던 행이 사라질 위기에 있다면 삭제되지 않고 해당 FK를 NULL로 바꿔주는 옵션이다.
📌 6. VIEW에 대해서 설명해주세요.
뷰는 데이터베이스 객체 중 하나입니다.
데이터베이스 객체란 테이블이나 인덱스 등 데이터베이스 안에 정의하는 모든 것을 말합니다.
반면 SELECT 명령은 객체가 아닙니다.
SELECT 명령에 이름을 지정할 수도 없고 데이터베이스에 등록되지도 않기 때문입니다.
이처럼 본래 데이터베이스 객체로 등록할 수 없는 SELECT 명령을
객체로서 이름을 붙여 관리할 수 있도록 한 것이 뷰입니다.
SELECT 명령은 실행했을 때 테이블에 저장된 데이터를 결과값으로 반환합니다.
따라서, 뷰를 참조하면 그에 정의된 SELECT 명령의 실행결과를 테이블처럼 사용할 수 있습니다.
뷰는 SELECT 명령을 기록하는 데이터베이스 객체입니다.
뷰를 작성하는 것으로 복잡한 SELECT 명령을 간략하게 표현할 수 있습니다.
📌 7. SELECT 절의 처리순서에 대해서 설명해주세요.


1. 해당 데이터가 있는 곳을 찾아가서 (FROM)
가장 먼저 처리되며, 관련된 테이블이나 뷰, 서브쿼리 등에서 데이터를 가져옵니다.
2. 조인 조건을 확인하고 (ON)
3. 테이블을 병합한다.(JOIN)
4. 조건에 맞는 데이터만 가져와서 (WHERE)
앞에서 걸러진 데이터에 대해 조건을 적용하여 필터링합니다.
5. 원하는 데이터로 가공(특정 컬럼으로 데이터 그룹화) (GROUP BY)
WHERE 절까지 거쳐온 데이터를 필요한 경우 그룹화합니다.
6. 가공한 데이터에서 조건에 맞는 것만 (데이터 추출조건 확인) (HAVING)
WHERE 절과 유사하지만, 그룹화된 결과에 대해 작동합니다.
7. 뽑아내서 (SELECT)
필터링하고 그룹화된 결과로부터 특정 컬럼을 선택합니다. 이 때, 집계 함수나 계산된 표현식도 포함될 수 있습니다.
8. 중복제거하고 (DISTINCT)
9. 정렬하고 (ORDER BY)
10. 지정된 범위를 벗어나는 행을 제거한다. (LIMIT / OFFSET)
최종 결과 집합에서 일정 범위의 데이터만을 반환하기 위해 사용됩니다.
위 순서는 데이터베이스 쿼리 엔진이 쿼리를 논리적으로 어떻게 처리할 지 결정하는 데 사용됩니다.
중요한 점은 SELECT 절이 실제로 데이터를 선택하는 동작은 뒤에서 일어나며
초기 단계에서는 데이터를 가져오고 필터링하는 작업이 먼저 이루어진다는 것입니다.
📌 8. SELECT ~ FOR UPDATE 구문에 대해서 설명해주세요.
"특정 레코드를 수정하려고 SELECT 하는 중이야~ 그러니까 다른 사람들은 특정 레코드에 손대지마!!!"라고 하는 구문입니다. 특정 레코드를 선택하고 해당 레코드에 대해 업데이트할 의도가 있음을 데이터베이스 시스템에 알립니다.
이 구문을 사용하면 해당 레코드에 대한 동시 업데이트를 방지하기 위해 데이터베이스에서 레코드를 잠그게 됩니다.
조금 딱딱한 표현으로는 동시성 제어를 위해 특정 데이터(ROW)에 대한 배타적 LOCK을 거는 기능입니다.
* 배타적 LOCK : 이 LOCK을 걸면 다른 트랜잭션에서 읽기와 쓰기가 모두 불가능합니다. 배타적 LOCK은 쿼리로 보면 SELECT ~ FOR UPDATE로 나타낼 수 있습니다.
예를들어 SELECT seat MOVIE WHERE movie_num = 5 FOR UPDATE 라고 실행하면
이 구문을 실행한 세션이 특정 레코드에 대해 수정할 때까지 LOCK이 걸립니다.
따라서 SELECT 후 UPDATE까지 실행하고 LOCK을 해제하면
다른 세션이 해당 레코드에 접근할 수 없습니다.
📌 9. GROUP BY절에 대해서 설명해주세요.
말 그대로 그룹으로 묶어주는 역할을 합니다.
동일한 값을 가진 컬럼을 그룹으로 묶어서 요약하기 위해서 사용합니다.
행 집합에서 요약된 행 그룹을 생성할 때 사용됩니다.
이 절은 집계 함수(ex) COUNT, MAX, MIN, SUM, AVG 등)와 함께 사용되어,
하나 이상의 컬럼을 기준으로 데이터를 그룹화하고 해당 그룹에 대해 계산을 수행합니다.
ex) 각 국가별 고객의 수를 알고 싶을 때, 성별로 제품의 구매량을 알고 싶을 때
아래와 같이 GROUP BY로 지정된 컬럼은 SELECT절에 명시되어야하며,
그룹화되지 않는 컬럼에는 집계함수를 적용해야합니다.
SELECT customer_id, SUM(purchase_amount)
FROM purchases
GROUP BY customer_id;
📌 10. ORDER BY절에 대해서 설명해주세요.
SQL 쿼리에서 결과 집합의 행을 정렬하는데 사용됩니다.
이 절을 사용하면 선택한 데이터를 특정 컬럼의 값에 따라 오름차순(ASC), 내림차순(DESC)으로 정렬할 수 있습니다.
콤마를 사용해 여러 컬럼을 지정할 수 있습니다.
고객의 이름을 알파벳 순으로 정렬하기 위해 아래의 예시와 같이 작성할 수 있습니다.
SELECT customer_name, customer_id
FROM customers
ORDER BY customer_name ASC;
📌 11. INNER JOIN과 OUTER JOIN의 차이점에 대해서 설명해주세요.
INNER JOIN과 OUTER JOIN의 차이점
INNER JOIN의 경우 두 테이블 간의 교집합에 해당하는 데이터만 반환합니다.
조인하는 양쪽 테이블에서 일치하는 행이 없으면, 그 행은 결과에 나타나지 않습니다.
OUTER JOIN의 경우 두 테이블 간의 합집합에 해당하는 데이터를 반환합니다. (FULL OUTER JOIN의 경우)
결국, INNER JOIN은 더 엄격한 매칭을 요구하며, 관련된 데이터만을 결과로 제공하는 반면, OUTER JOIN은 더 포괄적인 데이터 세트를 제공하며, 일치하는 행이 없는 경우에도 테이블의 행을 결과에 포함시키는 데 사용됩니다.

통상적인 JOIN의 경우가 Inner JOIN입니다.
이 Inner JOIN 쿼리를 사용하면 B와 매칭이 되는 A의 부분의 데이터들을 반환합니다.
즉, A와 B 두 테이블에 모두 지정한 열의 데이터가 있어야합니다. (교집합)
예시는 아래와 같습니다.
SELECT *
FROM Table_A A
INNER JOIN Table_B B
ON A.Key = B.Key;

Outer JOIN은 FULL OUTER JOIN또는 FULL JOIN이라고도 불립니다.
SQL에서 두 테이블 간의 조인을 수행할 때,
일치하는 행이 없는 경우에도 행을 반환하도록 설계된 조인입니다.
위 OUTER JOIN은 A테이블과 B테이블 모두의 모든 행을 반환합니다.
A또는 B의 테이블에서 일치하는 행이 없는 경우,
각각의 결과에 NULL 값이 포함되어 반환됩니다.
SELECT A.*, B.*
FROM A
FULL OUTER JOIN B ON A.key = B.key;
OUTER JOIN은 데이터베이스에 관계 데이터를 유연하게 조회할 때 유용하며,
특히 관계된 테이블 간에 일치하는 데이터가 없는 경우에도 정보를 얻고자 할 때 사용됩니다.
📌 12. LEFT OUTER JOIN, RIGHT OUTER JOIN에 대해서 설명해주세요.
OUTER JOIN의 종류로는 다음과 같이 세가지가 있고,
앞서 위에서 설명한 FULL OUTER JOIN을 제외하고 LEFT OUTER 와 RIGHT OUTER에 대해 설명합니다.

LEFT OUTER JOIN으로 왼쪽 테이블의 모든 값이 출력되는 조인입니다.
SELECT <select_list>
FROM Table_A A
LEFT JOIN Table_B B
ON A.Key = B.Key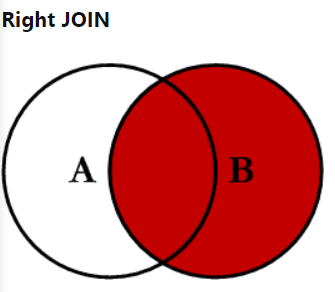
RIGHT OUTER JOIN으로 오른쪽 테이블의 모든 값이 출력되는 조인입니다.
SELECT <select_list>
FROM Table_A A
RIGHT JOIN Table_B B
ON A.Key = B.Key
📌 13. CROSS JOIN에 대해서도 설명해주세요.
자주 쓰이진 않지만 알아두면 좋은 JOIN입니다.
두 테이블 A, B가 있을 때 이를 1개 행씩 결합하는 조인입니다.
다시말해 테이블 A의 행 1개가 테이블 B의 모든 행에 하나씩 결합됩니다.
예를들어
A에 행이1개, B에 행이 5개 있으면 -> 1*5 = 5번 조인
A에 행이 2개, B에 행이 3개 있으면 -> 2*3 = 6번 조인되는 것입니다.
📌 14. 서브쿼리에 대해서 설명해주세요.
다른 쿼리 내부에 포함되어 있는 SELECT 문을 의미합니다.
하나의 SQL문 안에 포함되어 있는 또 다른 SQL문을 말합니다.
서브쿼리를 포함하고 있는 쿼리를 외부쿼리라고 부르며,
서브쿼리는 내부쿼리라고도 부릅니다.
서브쿼리는 괄호로 감싸져서 표현되며, 단일 행 또는 복수 행 비교 연산자와 함께 사용 가능합니다.
ORDER BY를 사용하지 못합니다.
📌 15. DROP, TRUNCATE, DELETE에 각각에 대해 설명해주세요. 어떤차이가 있나요?
DROP
테이블 자체를 데이터베이스에서 완전히 삭제하는 명령어입니다.
테이블 구조, 인덱스, 행 관련된 제이갸 조건 및 트리거 등 모든 것이 삭제됩니다.
롤백이 불가능하며, 한번 실행하면 테이블은 백업이나 복구 명령을 사용하지 않는 이상 복구할 수 없습니다.
TRUNCATE
테이블의 모든 행을 빠르게 삭제합니다.
TRUNCATE는 DELETE보다 빠르게 작동하며, WHERE절을 사용할 수 없습니다.
테이블의 구조와 인덱스는 그대로 남겨두고, 데이터만 삭제합니다.
일반적으로 테이블을 리셋하는데 사용됩니다.
DELETE
테이블에서 하나 이상의 행을 조건에 따라 삭제합니다.
WHERE절을 사용하여 특정 조건을 만족하는 행만을 삭제할 수 있습니다.
행 단위로 데이터를 삭제하며, 트랜잭션의 일부로 실행되어 롤백이 가능합니다.
삭제한 각 행에 대해 로그를 작성하기 때문에 대량의 데이터를 삭제할 때는 상대적으로 느릴 수 있습니다.
📌 16. DISTINCT에 대해서 설명해주세요. 사용해본 경험도 설명해주세요.
중복된 결과를 제거합니다.
DISTINCT를 사용하면 조회된 결과에서 중복된 데이터를 1개만 납깁니다.
예시로 아래와 같은 테이블이 있다고 가정합니다.
column1 | column2
--------|--------
A | 1
B | 1
A | 1
B | 2
A | 2SELECT DISTINCT column1, column2 FROM table;
쿼리를 실행하면
column1 | column2
--------|--------
A | 1
B | 1
B | 2
A | 2위와 같은 결과를 얻을 수 있습니다.
예시에서는 컬럼을 여러개 지정하였습니다.
DISTINCT 키워드를 사용할 때 여러 컬럼을 명시하면, 그 컬럼들의 조합에서 중복되는 데이터를 제거한 후 결과를 반환합니다.
지정된 모든 컬럼의 값이 동일한 행은 중복으로 간주되어 결과에서 한번만 나타나는 것입니다.
📌 17. SQL Injection 공격이 무엇인지 어떻게 공격을 예방할 수 있는지 설명해주세요.
SQL Injection 공격은 코드 인젝션의 한 기법으로
클라이언트의 입력값을 조작하여 서버의 데이터베이스를 공격할 수 있는 공격방식을 말합니다.
주로 사용자가 입력한 데이터를 제대로 필터링, 이스케이핑하지 못했을 경우에 발생합니다.
쉬운 난이도의 공격에 비해 파괴력이 어마어마하기 때문에 시큐어 코딩을 하는 개발자라면 가장 먼저 배우게 되는 내용입니다.
공격을 예방할 수 있는 방법으로는 아래와 같은 방법이 있다.
1) Prepared Statements (Parameterized Queries) 사용하기
SQL 쿼리를 컴파일하고, 사용자 입력을 파라미터로 전달하는 방법입니다. 대부분의 프로그래밍 언어와 데이터베이스 관리 시스템에서 지원합니다.
예시 (Java의 PreparedStatement):
String query = "SELECT * FROM users WHERE username = ? AND password = ?";
PreparedStatement pstmt = connection.prepareStatement(query);
pstmt.setString(1, username);
pstmt.setString(2, password);
ResultSet results = pstmt.executeQuery();
2) ORM (Object-Relational Mapping) 사용하기
ORM 라이브러리는 SQL Injection 공격에 대해 기본적으로 방어적인 코드를 생성합니다.
3) 입력 값 검증하기
사용자 입력을 받기 전에, 입력 데이터가 예상된 형식에 맞는지 검증합니다.
4)Stored Procedures 사용하기
로직을 데이터베이스에 저장해두고, 애플리케이션에서는 이를 호출만 하는 방식입니다. 하지만 잘못 구현된 경우 여전히 취약할 수 있습니다.
5) 계정 권한 최소화하기
애플리케이션에서 사용하는 데이터베이스 계정은 필요한 최소한의 권한만 가지도록 합니다.
6) 에러 메시지 관리하기
데이터베이스 오류 메시지가 사용자에게 그대로 노출되지 않도록 합니다. 공격자가 구조를 유추하는 데 사용될 수 있습니다.
7) 웹 애플리케이션 방화벽 (WAF) 사용하기
의심스러운 트래픽과 공격 시도를 차단하는 보안 시스템을 사용합니다.
-> SQL Injection 공격과 해결방법이 다소 어렵게 느껴진다.
자료 조사를 더 해봐야겠다.
📌 18. 알고 있는 SQL 안티패턴이 있다면 설명해주세요.
SQL 안티패턴(AntiPatterns)이란?
테이터베이스 설계 및 쿼리 작성 시
흔히 발생하는 비효율적이거나 잠재적으로 문제를 일으킬 수 있는 일련의 잘못된 접근 방식을 말합니다.
이러한 안티패턴들은 처음에는 빠르고 간단한 해결책처럼 보일 수 있지만, 장기적으로 보았을 때 성능 저하, 유지보수의 어려움, 논리적 오류, 데이터 무결성 문제 등 다양한 부작용을 초래할 수 있습니다.
몇가지 일반적인 SQL 안티패턴의 예는 다음과 같습니다.
갓 객체 (God Object)
데이터베이스에 거의 모든 정보를 담고 있는 거대하고 복잡한 테이블을 만드는 것.
컬럼 확장 (Column Creep)새로운 데이터를 저장하기 위해 지속적으로 테이블에 새 컬럼을 추가하는 것
EAV (Entity-Attribute-Value)
유연한 데이터 모델링을 위해 키-값 쌍을 저장하는 방식으로, 쿼리가 복잡해지고 성능이 저하될 수 있음.
다중값 컬럼 (Multi-valued Columns)
하나의 컬럼에 여러 값을 저장하는 것, 예를 들어 콤마로 구분된 리스트. 이는 정규화 원칙에 어긋나며 쿼리를 복잡하게 만듦.
암호화되지 않은 비밀번호 (Plaintext Passwords)
비밀번호를 암호화 없이 그대로 저장하는 것.
조인 남용 (Overuse of Joins)
필요 이상으로 많은 조인을 사용하여 쿼리의 복잡성과 성능 저하를 일으키는 것
임피던스 불일치 (Impedance Mismatch)
애플리케이션의 객체 모델과 데이터베이스의 관계 모델 간의 구조적 차이를 무시하고 강제로 매핑하는 것
매직 넘버 (Magic Numbers)
코드 내에서 의미를 명확히 설명하지 않은 숫자를 직접 사용하는 것
나쁜 냄새가 나는 SQL (Smelly SQL)
쿼리가 너무 복잡하거나 길어서 읽기 어렵고, 유지보수가 어려운 코드.
안티패턴을 피하기 위해서는 데이터베이스 정규화, 코드 리팩토링, 성능 최적화, 보안 강화 등의 방법을 적절히 활용하는 것이 중요합니다.
📌 19. 페이지네이션을 구현한다고 했을때 쿼리를 어떻게 작성해야할까요?
대량의 데이터를 하나의 페이지에 표시하는 것은
기능적으로도 속도 측면에서도 효율적이지 못하므로
일반적으로 페이지 나누기(페이지네이션 pagination) 기능을 사용합니다.
커뮤니티 사이트 등에서 게시판 하단 부분에 [ 1 2 3 4 5 다음 ] 등으로 표시된 것이 그 예입니다.
이 페이지 나누기 기능은 LIMIT를 사용해 간단히 구현할 수 있습니다.
한 페이지당 5건의 데이터를 표시하도록 한다면 첫 번째 페이지의 경우 LIMIT 5로 결과값을 표시하면 될 것입니다.
그 다음 페이지에서는 6번째 행부터 5건의 데이터를 표시하도록 합니다.
이때 6번째 행부터라는 표현은 결과값으로부터 데이터를 취득할 위치를 가르키는 것으로,
LIMIT구에 OFFSET으로 지정할 수 있습니다.
SELECT 열명 FROM 테이블명 LIMIT 행수 OFFSET 위치;
SELECT * FROM Board LIMIT 5 OFFSET 5;
(LIMIT 5는 총 다섯 행을 나타내고, OFFSET 5는 6부터 시작한다는 것을 나타냅니다.)
OFFSET 뒤에는 시작할 행 -1로 기억해두면 편리합니다. (OFFSET 0은 생략가능합니다.)
-> OFFSET을 사용하지 않는 여러 방법들도 있다. 어떤 방법이 어떠한 경우에 좋은건지?에 대해 더 알아봐야겠다.
[참고 자료]
참조 무결성과 Cascade 옵션
안녕하세요! 조엘입니다! 관계형 데이터베이스를 다루다보면 CASCADE를 활용할 일이 많아요. 참조의 관계를 맺은 데이터베이스를 신뢰성 있는 상태로 유지하기 위함인데요! CASCADE 옵션이 무엇을
papimon.tistory.com
4.11 SELECT SQL의 논리적인 처리 순서
### 4.11 SELECT SQL의 논리적인 처리 순서 SELECT SQL 작성 시 실수하지 않도록 논리적인 처리 순서를 이해할 필요가 있다. SELECT SQL은 [그림…
wikidocs.net
SQL SELECT 문의 처리 순서
SQL SELECT문의 처리 순서를 정리했다.
velog.io
[Database] SELECT ~ FOR UPDATE 란?
SELECT ~ FOR UPDATE란 SELECT ~ FOR UPDATE 구문은 "데이터 수정하려고 SELECT 하는 중이야~ 다른 사람들은 데이터에 손 대지 마!" 라고 할 수 있습니다. 좀 더 딱딱한 표현으로는 동시성 제어를 위하여 특정
dololak.tistory.com
SELECT FOR UPDATE / JPA를 사용한 비관적 잠금
'동시성(Concurrency)' 웹 서비스에서는 다수의 사용자들이 데이터베이스에 동시에 접근하는 경우가 빈번하게 발생합니다. 때문에 데이터의 일관성에 대한 처리가 필요한데요. 이를 '동시성(Concurren
wildeveloperetrain.tistory.com
Visual Representation of SQL Joins
This article describes SQL Joins in a visual manner, and also the most efficient way to write the visualized Joins.
www.codeproject.com
SQL JOIN 예제 - INNER, LEFT, RIGHT, FULL, CROSS, SELF JOIN
SQL에서 두번째로 많이 쓰이는 JOIN에 대해 알아본다. [MEMBER]와 [ORDER] 라고 하는 두가지 가상의 테이블이 있다고 하자. 두 테이블은 이렇게 생겼다. SELECT * FROM [MEMBER] SELECT * FROM [ORDER] JOIN(결합)이란,
suy379.tistory.com
[DATABASE] 서브쿼리란? 서브쿼리 사용해보기
서브쿼리란? 하나의 SQL 문에 포함되어 있는 또 다른 SQL 문을 말합니다. 서브쿼리 사용시 주의사항 1. 서브쿼리를 괄호로 감싸서 사용한다.2. 서브쿼리는 단일 행 또는 복수 행 비교 연산자와 함께
mozi.tistory.com
SQL injection - 나무위키
여기서 "Robert'); DROP TABLE Students;--"학생을 "학생 이름" 자리에 넣을 경우 다음과 같은 명령문이 된다. 첫 번째 줄에서는 Robert라는 학생이 입력되었지만, 두 번째 줄에서 학생들의 데이터가 있는 테
namu.wiki
'CS 면접 준비' 카테고리의 다른 글
| 데이터베이스 스터디 회고 (0) | 2023.12.11 |
|---|---|
| 데이터베이스 5주차 스터디 정리 (2) | 2023.12.06 |
| 데이터베이스 4주차 스터디 정리 (1) | 2023.11.29 |
| 데이터베이스 3주차 스터디 정리 (1) | 2023.11.22 |
| 데이터베이스 1주차 스터디 정리 (0) | 2023.11.08 |